, 4 min read
Hashnode Markdown Bulk Import Is Troublesome
1. I have written more than 300 blog posts, see sitemap. I wanted to import them into Hashnode. As all these posts were already in Markdown format, it was obvious to use the "bulk import" feature in Hashnode. The Hashnode bulk import reads a zip-file. This zip-file contains individual Markdown files.
I had checked previously that this bulk import worked. Although, I had checked it with a zip-file with only a single Markdown file in it. I noticed that deleting a previous post makes the slug unusable for ever. I have written on this here: Deletion Troublesome in Hashnode.com. This behaviour occurs on import and on direct entry. It is therefore not an import-specific problem.
So I knew I could only import my posts once, and only once. Therefore I concatenated multiple posts into one file and checked the large post in Hashnode. I did this multiple times. With this procedure I figured out that MathJax support in Hashnode is quite "special". Also, many european characters, for example German umlaut characters, are not directly supported in Hashnode, they have to be replaced by their proper HTML equivalent.
The MathJax specialities and shortcomings are:
- Underscore in displaymath needs to be escaped with backslash.
- Double backslashes in displaymath need to be escaped with four backslashes and a newline.
- Negative whitespace (kerning)
\!needs to be escaped with backslash. - Star in displaymath needs to be escaped with backslash.
- When displaymath has lines starting with a minus or plus-sign, they need to be escaped with backslash.
The slug from my original blog posts had to be mapped to a schema without slashes, a.k.a. directories.
2. All these changes I incorporated into a Perl script saaze2hashnode, see below. Then I thought, importing would be easy. That turned out to be wrong. Instead, Hashnode is not able to import more than roughly 10 or 20 files. Also, each individual post has to be confirmed. If you have more than 300 posts, you have to confirm more than 300 posts!
 So I had to create multiple zip-files. Apparently every post returned with some error. From my roughly 300 posts, 4 didn't make it, even after trying multiple times. I got the impression that posts with references to images took longer than posts, which only contained text. It might be an issue with total size of all HTML elements which break some internal Hashnode boundaries. Below errors were experienced:
So I had to create multiple zip-files. Apparently every post returned with some error. From my roughly 300 posts, 4 didn't make it, even after trying multiple times. I got the impression that posts with references to images took longer than posts, which only contained text. It might be an issue with total size of all HTML elements which break some internal Hashnode boundaries. Below errors were experienced:
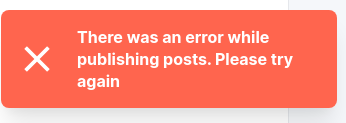 This error does not give any hint, what the exact cause of the problem is. In all my posts I only have references to images. There is no "direct" image, i.e., I did not upload any image to Hashnode.
This error does not give any hint, what the exact cause of the problem is. In all my posts I only have references to images. There is no "direct" image, i.e., I did not upload any image to Hashnode.
The Perl script saaze2hashnode is:
#!/bin/perl -W
# Convert Saaze Markdown to Hashnode Markdown
# 1. Insert reference to eklausmeier.goip.de at top of post
# 2. Change all href's (anchor and images) to eklausmeier.goip.de
# 3. YouTube and Twitter tags are converted to Hashnode embedly's format
# 4. Change LaTeX single dollar to \\( and \\)
# 5. Slug is blog-year-month-day-text.md
#
# Usage:
# ( let i=0; for f in `find . -name \*.md | sort`; do let i=i+1; saaze2hashnode $f | tee -a /tmp/hashnode/all1 > /tmp/hashnode/c$i; done )
use strict;
my ($n3dash,$nslug,$codeBlock,$displayMath) = (0,0,0,0);
my ($year,$hashnode,$goIP,$title) = ("","","","");
while (<>) {
if (/^---\s*/) {
++$n3dash;
} elsif ($n3dash == 1) {
if ( /^date:\s+"(\d\d\d\d)/ ) {
$year = $1;
} elsif (/^title:\s+("|)(.+)\s*$/) {
$title = $2;
$title =~ s/"$//;
} elsif ($nslug == 0 && length($year) == 4) {
my $fn = $ARGV;
$fn =~ s/\.md$//;
$fn = substr($fn,1 + rindex($ARGV,"/"));
$hashnode = "blog-" . $year . "-" . $fn;
$goIP = "blog/" . $year . "/" . $fn;
printf("slug: %s\n",$hashnode);
$nslug = 1;
}
} elsif ($n3dash == 2 && $nslug == 1) {
printf("\nThis post was automatically copied from [%s](https://eklausmeier.goip.de/%s) on [eklausmeier.goip.de](https://eklausmeier.goip.de/blog).\n\n",$title,$goIP);
$nslug = 2;
}
if (/^```/) {
s/^```(\w+)\s+.+/```$1/; # strip anything behind programming language
$codeBlock = 1 - $codeBlock;
}
s/\[more_WP_Tag\]//;
if ($codeBlock == 0) {
s/\[youtube\]\s*(.+?)\s*\[\/youtube\]/%\[https:\/\/www.youtube.com\/watch?v=$1\]/g;
s/\(\.\.\/\.\.\/\.\.\/(img|pdf)/\(https:\/\/eklausmeier.goip.de\/$1/g;
s/\.\.\/\.\.\/2(\d\d\d)\//https:\/\/eklausmeier.goip.de\/blog\/2$1\//g;
s/Ä/Ä/g;
s/Ö/Ö/g;
s/Ü/Ü/g;
s/ä/ä/g;
s/ö/ö/g;
s/ü/ü/g;
s/ß/ß/g;
s/ı/ı/g;
s/–/–/g;
s/—/–/g;
s/´/’/g;
s/’/’/g;
s/‘/’/g;
s/“/“/g;
s/”/”/g;
# s/°C/℃/g;
s/°/°/g;
s/§/§/g;
s/á/á/g;
s/é/é/g;
if (/^\$\$/) {
$displayMath = 1 - $displayMath; # flip flag
} else { # inline math
s/\$(.+?)\$/\\\\\($1\\\\\)/g; # replace $xyz$ with \\(xyz\\)
}
if ($displayMath == 1) {
if (/^\$\$(.+)\$\$/) { s/\$\$(.+)\$\$/\$\$\n$1\n\$\$/; $displayMath = 0; }
s/_/\\_/g; # Hashnode needs escaping of underscore
s/\\\\(\s*)/\\\\\\\\\n /g; # replace \\ with \\\\{newline}{single space}
s/\\!/\\\\!/g; # escaping \!
s/\\\{/\\\\\{/g; # escaping {
s/\\}/\\\\}/g; # escaping }
s/\*/\\*/g; # Hashnode needs escaping of star
s/^(\s*)\-/$1\\-/; # prevent Hashnode from taking minus as enumeration
s/^(\s*)\+/$1\\+/; # prevent Hashnode from taking plus as enumeration
}
}
print;
}
3. Those posts, which didn't make it through the importer, I tried to enter manually. I.e., I used saaze2hashnode script and then pasted the output into the browser window. Even then, Hashnode had trouble publishing them:
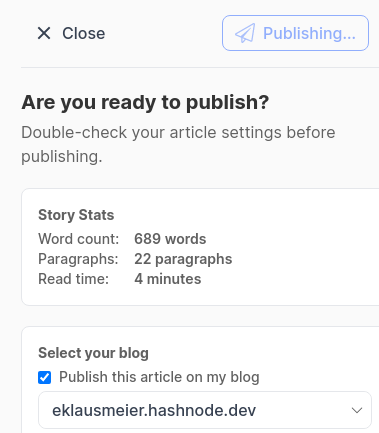
Above message showed for more than ten hours. After that I closed the window.
Obviously, the whole experience in importing and posting blog entries is not good.