, 6 min read
Performance Comparison Pallene vs. Lua 5.1, 5.2, 5.3, 5.4 vs. C
Installing Pallene is described in the previous post: Installing Pallene Compiler. In this post we test the performance of Pallene versus C, Lua 5.4, and LuaJIT. Furthermore we benchmark different Lua versions starting with Lua 5.1 up to 5.4.
1. Array Access. I checked a similar program as in Performance Comparison C vs. Lua vs. LuaJIT vs. Java and converted it to Pallene.
function lua_perf(N:integer, S:integer)
local t:{ {a:float, b:float, f:float} } = {}
for i = 1, N do
t[i] = {
a = 0.0,
b = 1.0,
f = i * 0.25
}
end
for j = 1, S-1 do
for i = 1, N-1 do
t[i].a = t[i].a + t[i].b * t[i].f
t[i].b = t[i].b - t[i].a * t[i].f
end
--io_write( t[1].a )
end
end
This Pallene program, which does no I/O at all, runs in 0.14s, and therefore runs two times slower than the LuaJIT, which finishes in 0.07s. This clearly is somewhat disappointing. Lua 5.4, as part of Pallene, needs 0.75s. So Pallene is roughly five times faster than Lua.
$ time ./lua/src/lua lua_perf/main.lua
real 0.14s
user 0.13s
sys 0
swapped 0
total space 0
Here, the calling main.lua routine is just
package = require "lua_perf.lua_perf"
N = 4000
S = 1000
package.lua_perf(N,S)
Runtimes are now:
- C (no optimization flags): 0.09s
- C: 0.02s
- Lua 5.1: 1.34s
- Lua 5.2: 1.49s
- Lua 5.3: 0.95s
- Lua 5.4: 0.72s
- LuaJIT: 0.07s
- Pallene: 0.14s
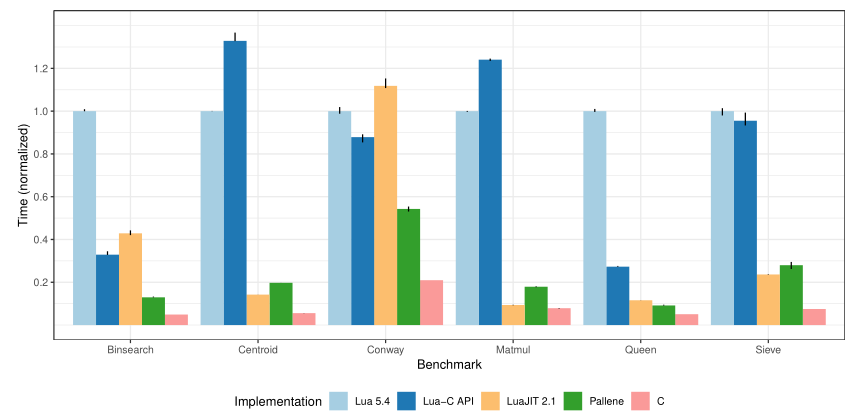
As explained in Pallene: A companion language for Lua, array handling in LuaJIT is still more efficient than in Pallene.
The only benchmark where LuaJIT is substantially faster than Pallene is Matmul. We have found that this difference is due to memory access. LuaJIT uses the NaN-boxing technique to pack arbitrary Lua values and their type tags inside a single IEEE-754 floating-point number [28]. In particular, this means that in LuaJIT an array of floatingpoint numbers consumes only 8 bytes per number, against the 16 bytes used by Lua and Pallene. This results in a higher cache miss rate and worse performance for Pallene.
2. Integer Computation. Below program computes the number of configurations for multiple chess queens to be positioned without attacking each other. It is the well known n-queen problem. Often times this is solved in a recursive fashion, but the most obvious program is non-recursive and uses goto-statements. Below code is in xdamcnt2.c on GitHub.
#define abs(x) ((x >= 0) ? x : -x)
/* Check if k-th queen is attacked by any other prior queen.
Return nonzero if configuration is OK, zero otherwise.
*/
//inline --> not faster, klm, 24-Apr-2020
int configOkay (int k, int a[]) {
int z = a[k];
for (int j=1; j<k; ++j) {
int l = z - a[j];
if (l == 0 || abs(l) == k - j) return 0;
}
return 1;
}
long solve (int N, int a[]) { // return number of positions
long cnt = 0;
int k = a[1] = 1;
int N2 = N; //(N + 1) / 2;
loop:
if (configOkay(k,a)) {
if (k < N) { a[++k] = 1; goto loop; }
else ++cnt;
}
do
if (a[k] < N) { a[k] += 1; goto loop; }
while (--k > 1);
a[1] += 1;
if (a[1] > N2) return cnt;
k = 2 , a[2] = 1;
goto loop;
}
Compiled the program with all optimization (-march=native -O3), then ran this program.
$ time xdamcnt2 1 12
n-queens problem.
2 4 6 8 10 12 14
1 0 0 2 10 4 40 92 352 724 2680 14200 73712 365596
D( 1) = 1
D( 2) = 0
D( 3) = 0
D( 4) = 2
D( 5) = 10
D( 6) = 4
D( 7) = 40
D( 8) = 92
D( 9) = 352
D(10) = 724
D(11) = 2680
D(12) = 14200
real 0.21s
user 0.21s
sys 0
swapped 0
total space 0
Above C code has been translated to Lua 5.1, which does not provide goto-statements. We deliberately chose Lua 5.1, because LuaJIT can only handle Lua 5.1 syntax. Only starting with Lua 5.2 the goto-statement is allowed in Lua. Not having a goto-statement required to use auxiliary variables, here called flag, then checking with if-statements. This file is called xdamcnt2.lua on GitHub.
-- Check if k-th queen is attacked by any other prior queen.
function configOkay (k, a)
local z = a[k]
local kmj
local l
for j=1, k-1 do
l = z - a[j]
kmj = k - j
if (l == 0 or l == kmj or -l == kmj) then
return false
end
end
return true
end
function solve (N, a) -- return number of positions
local cnt = 0
local k = 1
local N2 = N --(N + 1) / 2;
local flag
a[1] = 1
while true do
flag = 0
if (configOkay(k,a)) then
if (k < N) then
k = k + 1; a[k] = 1; flag = 1
else
cnt = cnt + 1; flag = 0
end
end
if (flag == 0) then
flag = 0
repeat
if (a[k] < N) then
a[k] = a[k] + 1; flag = 1; break;
end
k = k - 1
until (k <= 1)
if (flag == 0) then
a[1] = a[1] + 1
if (a[1] > N2) then return cnt; end
k = 2; a[2] = 1;
end
end
end
end
The Lua code was then translated to Pallene by adding the required types to each variable. This translation is straightforward. File is called xdamcnt2.pln on GitHub.
-- Check if k-th queen is attacked by any other prior queen.
function configOkay (k:integer, a:{integer}):boolean
local z:integer = a[k]
local l:integer
local kmj:integer
for j=1, k-1 do
l = z - a[j]
kmj = k - j
if (l == 0 or l == kmj or -l == kmj) then
return false
end
end
return true
end
function solve (N:integer, a:{integer}):integer -- return number of positions
local cnt:integer = 0
local k:integer = 1
local N2:integer = N --(N + 1) / 2;
local flag:integer
a[1] = 1
while true do
flag = 0
if (configOkay(k,a)) then
if (k < N) then
k = k + 1; a[k] = 1; flag = 1
else
cnt = cnt + 1; flag = 0
end
end
if (flag == 0) then
flag = 0
repeat
if (a[k] < N) then
a[k] = a[k] + 1; flag = 1; break;
end
k = k - 1
until (k <= 1)
if (flag == 0) then
a[1] = a[1] + 1
if (a[1] > N2) then return cnt; end
k = 2; a[2] = 1;
end
end
end
end
Runtimes are now:
- C (no optimization flags): 0.53s
- C: 0.2s
- Lua 5.1: 6.15s
- Lua 5.2: 7.2s
- Lua 5.3: 5.83s
- Lua 5.4: 3.92s
- LuaJIT: 0.58s
- Pallene: 0.32s
- Pallene with compiler optimization flags: 0.31s
This time Pallene is two times faster than LuaJIT, and it is 13-times faster than Lua 5.4. Additionally we observe that Lua 5.4 is faster than all previous versions by a large margin. Interesting enough, the C program only needs 60% of the Pallene running time.
3. Environment. All tests were done on an AMD FX-8120 Octacore processor with max. 3.1 GHz. This processor has 64 KiB L1 data cache.
$ lscpu
Model: 1
Model name: AMD FX(tm)-8120 Eight-Core Processor
CPU max MHz: 3100.0000
CPU min MHz: 1400.0000
L1d cache: 64 KiB
L1i cache: 256 KiB
L2 cache: 8 MiB
L3 cache: 8 MiB
This CPU runs Arch Linux 5.6.6 and gcc 9.3.0.
Above runtime comparisons are in line with the benchmarks in Pallene: A companion language for Lua.
Added 17-Jul-2020: Cited in LWN: What's new in Lua 5.4.
Added 27-Nov-2022: A strong contender to replace LuaJIT might be Haoran Xu's LuaJIT Remake (LJR). Also see Copy-and-Patch Compilation by Haoran Xu and Fredrik Kjolstad. Discussion on Hacker News.
Added 30-Oct-2023: Referenced in Dragonfly + BullMQ = massive performance. Dragonfly is a faster Redis variant, BullMQ is a Node.js library with queuing.