, 3 min read
Texts on Machine Learning
1. Optimization
Some texts from Elad Hazan.
- Introduction to Online Convex Optimization
- Lecture Notes: Optimization for Machine Learning
- Introduction to Online Control
Second order methods by James Martens et al.
- Deep learning via Hessian-free optimization
- On the importance of initialization and momentum in deep learning
Some texts by Florian Schäfer.
Anna Choromanska, Mikael Henaff, Michael Mathieu, Gérard Ben Arous, and Yann LeCun: The Loss Surfaces of Multilayer Networks
Muon Optimization.
- Keller Jordan: Muon: An optimizer for hidden layers in neural networks
- KIMI
- Jingyuan Liu et al.: Muon is Scalable for LLM Training
- Jennifer Wei: Going Beyond AdamW: A Practical Guide to the Muon Optimizer
- Jennifer Wei: Hopper: The Optimizer That Learns Parallelism 2x Faster Than Adam
Deep Learning with Python – François Chollet & Matthew Watson
2. Evolution Strategies at the Hyperscale
This method based on evolutionary strategies promises a 100-fold increase in training speed.
It is based on pure integer training, i.e., using int8.
That is the fastest supported datatype on a H100.
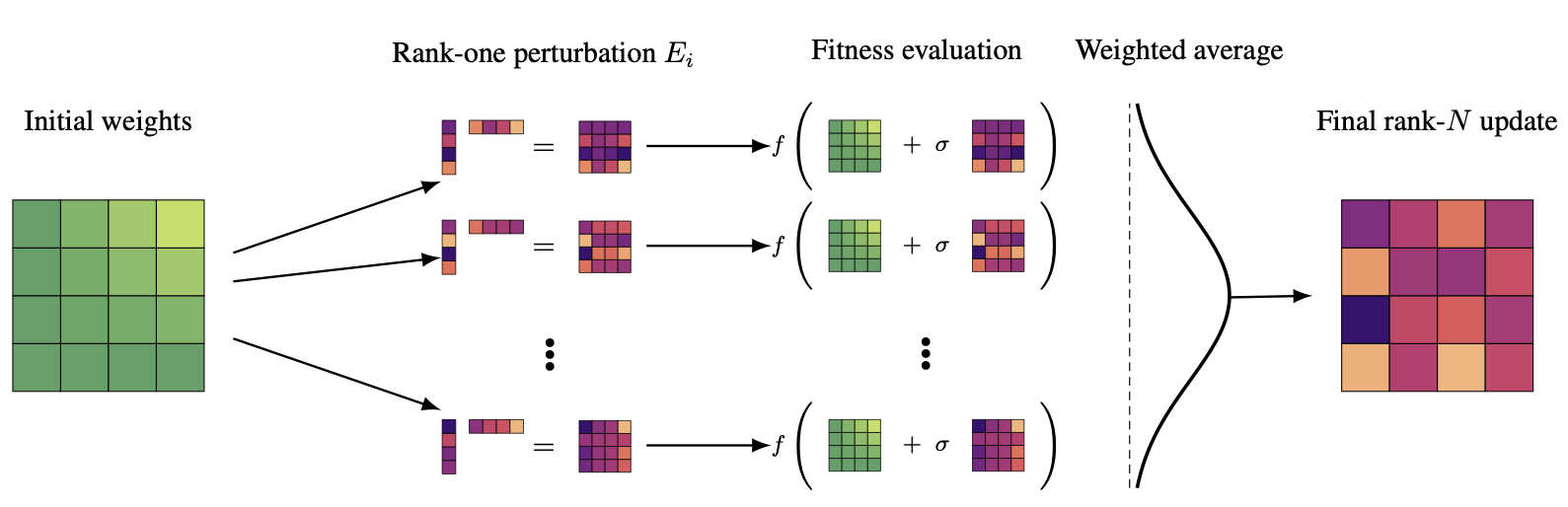
We introduce EGGROLL, a novel general-purpose machine learning algorithm that provides a hundredfold increase in training speed over naïve evolution strategies. EGGROLL practically eliminates the barrier between inference and training, allowing us to easily fine-tune LLMs for reasoning or train new architectures from scratch.Evolution Strategies (ES) is a class of powerful black-box optimisation methods that are highly parallelisable and can handle non-differentiable and noisy objectives. However, naïve ES becomes prohibitively expensive at scale on GPUs due to the low arithmetic intensity of batched matrix multiplications with unstructured random perturbations. We introduce Evolution Guided GeneRal Optimisation via Low-rank Learning (EGGROLL), fhich improves arithmetic intensity by structuring individual perturbations as rank-r-matrices, resulting in a hundredfold increase in training speed for billion-parameter models at large population sizes, achieving up to 91% of the throughput of pure batch inference.
We provide a rigorous theoretical analysis of Gaussian ES for high-dimensional parameter objectives, investigating conditions needed for ES updates to converge in high dimensions. Our results reveal a linearising effect, and proving consistency between EGGROLL and ES as parameter dimension increases. Our experiments show that EGGROLL:
- enables the stable pretraining of nonlinear recurrent language models that operate purely in integer datatypes,
- is competitive with GRPO for post-training LLMs on reasoning tasks, and
- does not compromise performance compared to ES in tabula rasa RL settings, despite being faster.
3. Pruning + Distillation
- To prune, or not to prune: exploring the efficacy of pruning for model compression
- Pruning vs Quantization: Which is Better?
- A Survey on Deep Neural Network Pruning-Taxonomy, Comparison, Analysis, and Recommendations
- A survey of model compression techniques: past, present, and future
- Structural Pruning of Large Vision Language Models: A Comprehensive Study on Pruning Dynamics, Recovery, and Data Efficiency